- 作者帖子

空层游客来源:南巡盛典 : 一百二十卷 / 高晉 ... [et al.] 纂輯., Nan xun sheng dian : yi bai er shi juan / Gao Jin ... [et al.] zuan ji. - Digital PUL (princeton.edu)
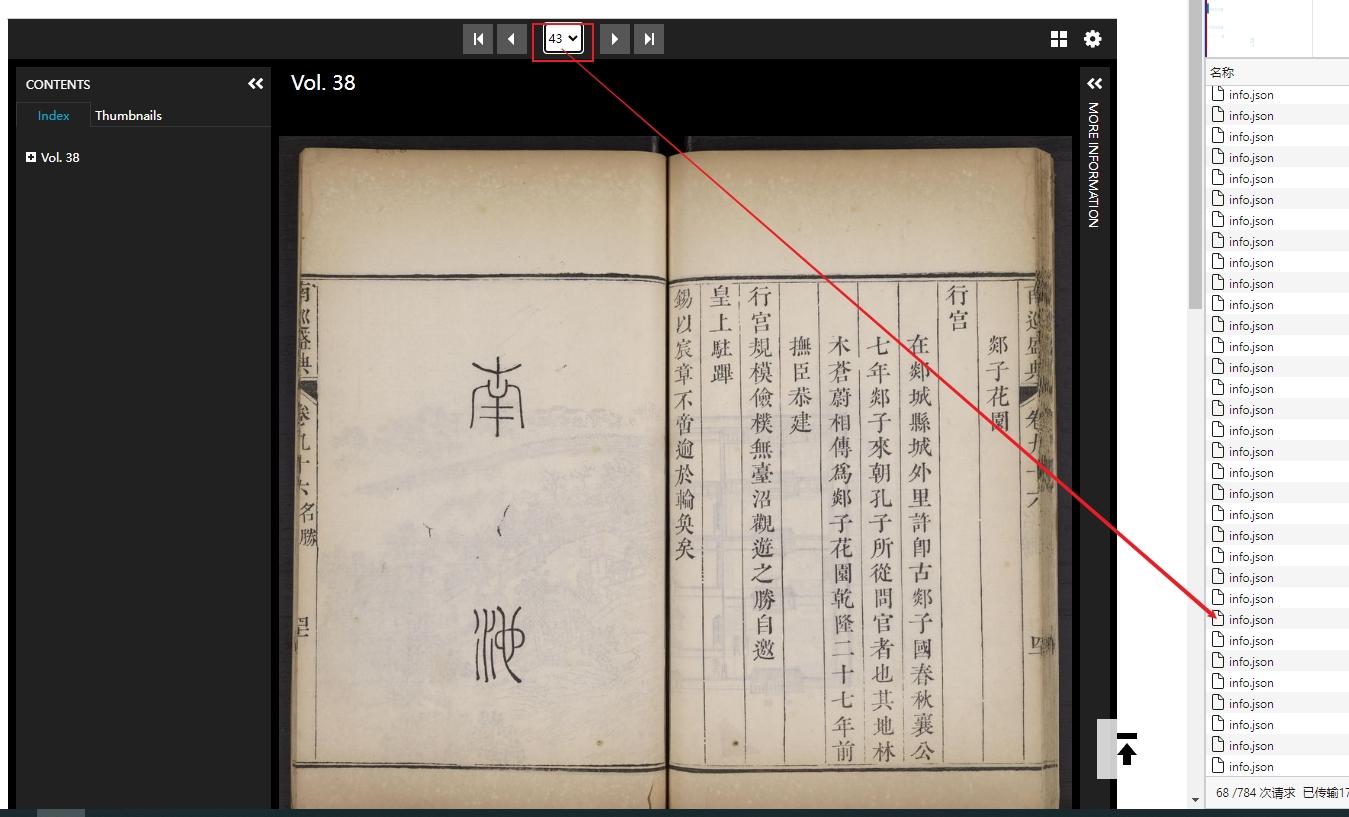
此卷有58副图(提供下载只是需要一个一个点击)。打开F12,然后每幅图都浏览一次就会得到右边的这些JSON文件,JSON里的下载链接没有规律没办法批量生成网址,需要一个一个点开再复制稍微有点繁琐,想咨询下各位老师有没有批量采集JSON文件里的某个网址的浏览器插件或者软件,然后再配合未曾老师的批量下载脚本,可以节约大量时间。

xiaopengyou游客用bookgetj就可以下載吧,分辨率是8322*7330
xiaopengyou游客@xiaopengyou #45604
不好意思多打了j, 是bookget下載神器
空层游客@xiaopengyou #45604
感谢回复,我的想法是如果找到这种批量提取网址软件的话,bookget没有收录的网站也可以比较方便的批量下载了。
xiaopengyou游客
zhudw游客@空层 #45610
@xiaopengyou #45611
因为 xiaopengyou 这位朋友太热心了,我也跟个帖。
LZ要做到真正意义上的【通用】,只有靠勤劳的双手,自己学编程,自己根据不同的网站写程序。如果你愿意走这条路,可以学一下python或者javascript,基本上学一个月可以满足需求。
常规IIIF网站,只要你能找到manifest.json网址,就可以用bookget生成批处理,然后用批处理运行dezoomify-rs就可以下载,也不用手动一个一个复制URL。(具体做法参见bookget手册)
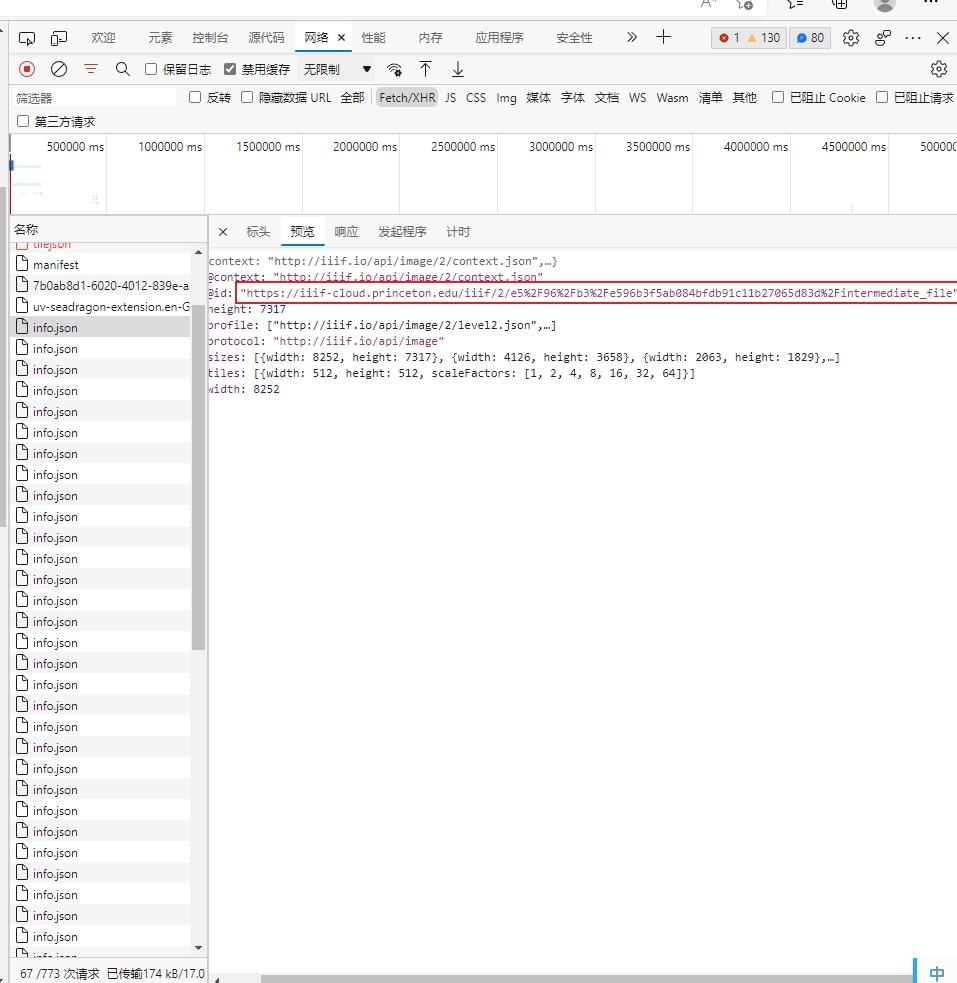
但是普林斯顿大学东亚图书馆,它是变异IIIF网站,它的manifest不是标准的。你看到info.json的时候,已经是通过几次的网络请求,才能看到一个URL。
因此在这个意义上,就不存在通用的工具。除非你是针对它而编写的。
空层游客
空层游客@xiaopengyou #45611
再次感谢!
xiaopengyou游客@zhudw #45621
還是得專業的高人解答,個人只是舉手之勞,把 先生及 未曾先生無償分享過的下載工具提一提,方便來書格平台的朋友使用吧了,專業的程序語言與技術,電腦小白如我也實在不懂哈。
未曾管理员我觉得了解一下正则表达式
或可使用EmEditor的正则提取功能
zhudw游客@空层 #45603
不好意思,刚才我测试了一下。你发的这个图书,可以用bookget生成批处理脚本。
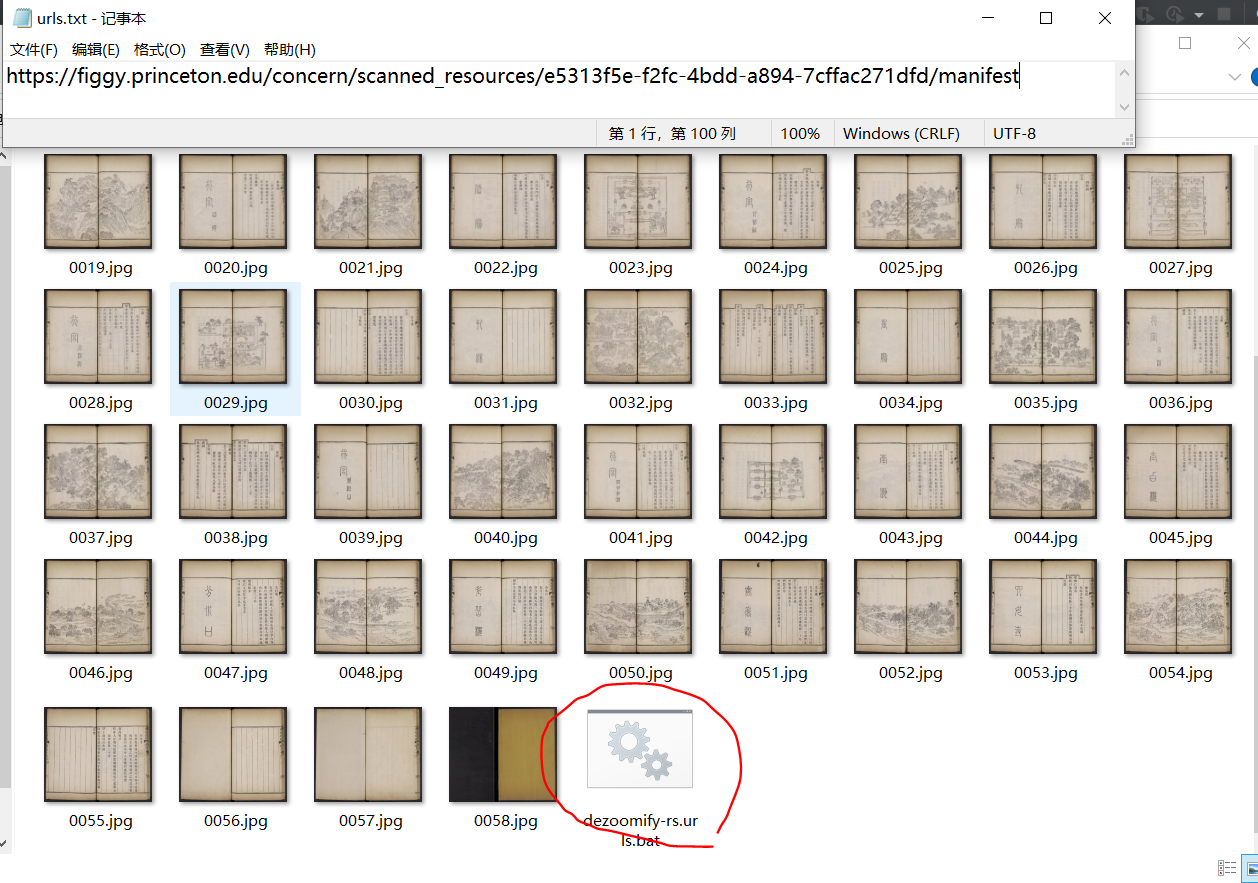
1、找到 manifest(例如普林斯顿在浏览器开发者工具中,能看到三个含有manifest的网址,你用最后一个manifest)
2、粘贴到urls.txt中
3、修改config.ini文件,设置AutoDetect = 2,保存
4、运行bookget,会得到下载的图片,和dezoomify-rs.urls(二选一,可以用任意一种方式下载)。
(其它的IIIF网站,也参考这种方法。你要学的是找到正确的 manifest。)
xiaopengyou游客@zhudw #45629
請教高人
同樣下這本書,改成用dezoomify-rs.urls下載並沒有比直接用bookget下載快啊,而且下載後圖片分辨率還是一樣的。
是否這個方法是用在bookget沒收錄的圖書館但有iiif標記的下載?
xiaopengyou游客@xiaopengyou #45631
而且比較一下,用dezoomify-rs.urls下載圖片的大小,比直接用bookget下載圖片的大小,大了近一倍
zhudw游客@xiaopengyou #45631
这是JPEG, quality: 80的导致的,一般图书馆提供的都是JPG品质80或90的图片,如果需要品质100的图,是要用dezoomify-rs.urls脚本,以拼图的方式下载的。
是的,bookget没有收录的图书馆,只要它是标准IIIF的,都可以用这种方式下载。
xiaopengyou游客@zhudw #45634
了解了,非常感謝!
zhudw游客@空层 #45640
可以按以下思路检查原因:
1、或许是找的manifest 不对,可以用前文我帖出来的试试。
2、不论是修改 urls.txt、或是修改config.ini都需要保存文件。
3、确保你用的是最后一个版本bookget v0.2.4(可以从原帖下载)
空层游客@zhudw #45642
可以了,是因为config.ini修改后没有保存。拜谢!
恩县布衣游客这部书未曾先生在书格发布过
fans游客@zhudw #45634
请问:如果将jpg换成png, 文件会增加较大,图片的质量是进一步提高了? 还是与jpg格式的文件一样? 还是根据不同网站实际提供的文件类型有关系?如提供的是jpg格式的,那么好像就无所谓了,如提供的是PNG格式的是不是就有意义了?谢谢解答
tigershuai游客@fans #45711
这要看网站提供的原图是什么格式,如果原图就是jpg格式,那无论转成什么格式,图片质量也不会有实质改变。
zhudw游客
He220803C游客@未曾 #45627
您好!未曾先生,如果不同的提取内容,应该怎样编写正则表达式,請先生赐教,谢谢!
fan1026游客确实很难,台北故宫的地址有些细节图多的还不是连续的比如0000000.json~0000030.json一共31个图片信息,复制地址时候只要修改后面的数字就行,结果有些作品是跳字母的,中间会少一个,这样用排列就会少下载2个图片!会py的话,估计只要用插件版的dezoomfy源码中能获取info网址的那一段写个py爬一下就行了!大体过程应该是打开网站图片的iiif模式的地址,然后get到info网址(id)
- 作者帖子
正在查看 24 个帖子:1-24 (共 24 个帖子)
正在查看 24 个帖子:1-24 (共 24 个帖子)
正在查看 24 个帖子:1-24 (共 24 个帖子)
