- 作者帖子

张飞白游客
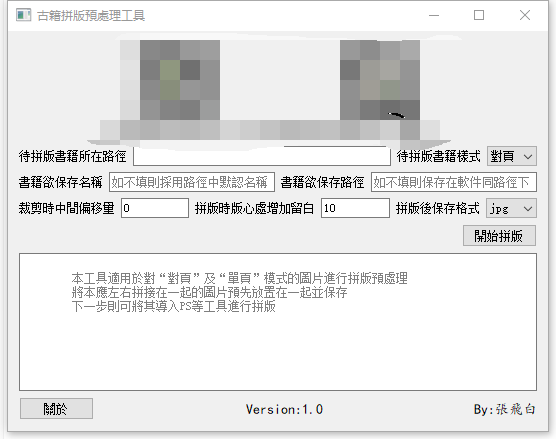
看到有朋友在寻找将两页扫描成单页的古籍图片拼接成一页的工具。鄙人刚好开发过一款这样的工具,现分享出来,有兴趣的朋友可以下载试用。工具长这样:
拼接后的效果如下:
PS:
1.这款软件原来是作为用PS拼接古籍的前置,主要是预先将筒子页的两边预拼合在一起,然后再用PS进行精细调整,所以称为“古籍预拼接工具”。我曾出过两期视频 ,见下:
2.这个工具只是一个预处理工具,即先将筒子页的两边自动预拼接在一起,预拼接的效果好坏取决于图片的品相。上图效果算比较好的,如果两半大小、分辨率等相差很大,效果可能 较差——自动的嘛,没有经过人工干预。
当然,应该是能满足那位仁兄的要求了。
晕水的鱼游客谢谢分享
天天游客软件在分享一下行吗
浮山樵夫游客你好 ,软件可以共享一下么
Chat游客Q: 写一段python代码,批量把某个文件夹内所有的图片,每两张合成一页,最后做成一个PDF文档。
A:
`python
# -*- coding:utf-8 -*-
from PIL import Image
import os
from fpdf import FPDF# 定义保存图片的路径
images_path = 'xxx/xxx'# 打开一个pdf
pdf=FPDF()# 循环遍历所有图片
num=1
for item in os.listdir(images_path):
# 设置每页有2张图片
if num%2==1:
# 获取图片的完整路径
img_path = os.path.join(images_path,item)
# 添加图片,第一个参数是图片地址,第二个参数是图片位置,第三个参数是图片大小
pdf.add_page()
pdf.image(img_path,x=None,y=None,w=200,h=200)
else:
img_path = os.path.join(images_path,item)
pdf.image(img_path,x=None,y=None,w=200,h=200)
num+=1# 保存pdf
pdf.output('xxx.pdf','F')
`
Q:
老沙游客@张飞白 #53404
怎联系到你,拼版工具在那下载
姑苏飘雪游客同求工具软件个人版 下载链接
姑苏飘雪游客求软件下载链接
- 作者帖子
正在查看 8 个帖子:1-8 (共 8 个帖子)

正在查看 8 个帖子:1-8 (共 8 个帖子)
正在查看 8 个帖子:1-8 (共 8 个帖子)
