标签: 技术分享
- 作者帖子

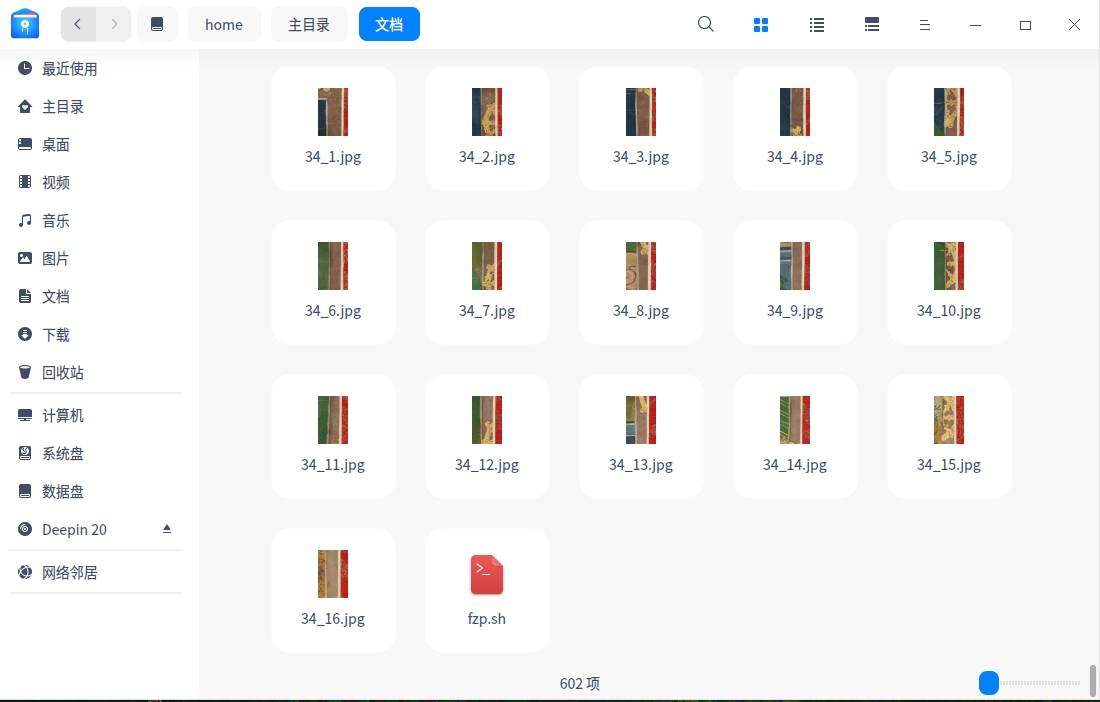
tigershuai游客一些高清图需要下载小图块后拼接成一张完整的大图,请问先生有什么好的办法能批量下载这些小图块呢?比如如下这张图:
tigershuai游客或是一次性批量得到小图块的地址列表,望先生赐教。
未曾管理员@tigershuai #45925
你有Linux的运行环境吗?你熟悉其bash脚本运行吗?我只会写这个脚本
tigershuai游客@未曾 #45933
我有统信系统的电脑,但不太懂bush
未曾管理员
未曾管理员贴一下bash脚本,供参考
需要安装imagemagick,需要填入图片的root.xml文件地址
#!/bin/bash # Script to download tiles # Last update: 20220520 dzi="https://www.nara-wu.ac.jp/aic/gdb/mahoroba/y29/taimanerikuyouzu/resources/tanjoji_taimanerikuyouzu/root.xml" xml=
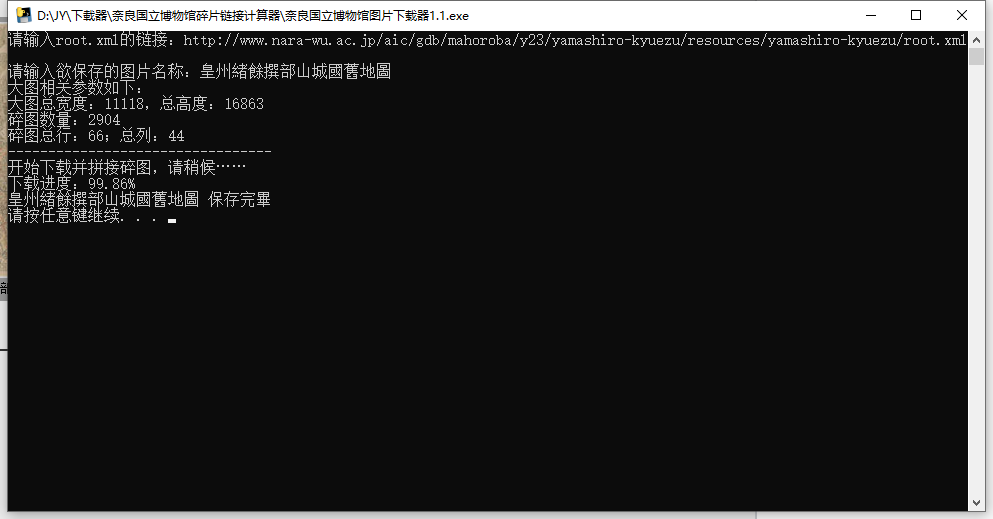
curl -s ''$dzi''wi=(echo $xml | sed 's/.*width=\"\([0-9]*\).*//g') hi=(echo $xml | sed 's/.*height=\"\([0-9]*\).*//g') tsize=(echo $xml | sed 's/.*tilewidth=\"\([0-9]*\).*//g') url=echo ${dzi/root.xml/}"0/" cols=$((wi/tsize+1)) rows=$((hi/tsize+1)) for ((i = 0; i < $rows; i++)) do string='' for ((j = 0; j < $cols; j++)) do if [ $i -lt $((rows-1)) ] ; then nh=$tsize else nh=$((hi%tsize)) fi if [ $j -lt $((cols-1)) ] ; then nw=$tsize else nw=$((wi%tsize)) fi num1=echo $((j*tsize))|awk '{printf("%05d\n",$0)}'num2=echo $((i*tsize))|awk '{printf("%05d\n",$0)}'num3=echo $nw |awk '{printf("%05d\n",$0)}'num4=echo $nh |awk '{printf("%05d\n",$0)}'image=$num1$num2$num3$num4'.jpg' img=$j'_'$i'.jpg' file=$url$image echo $file string=$string' '$img wget --no-check-certificate --user-agent="Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.204 Safari/534.16" -c -t 40 -O $img $file -q done montage $string -tile $cols''x1 -mode concatenate row$i.jpg done string='' for ((i = 0; i<$rows; i++)) do string=$string' 'row$i.jpg done if [ ! -d "downloads" ]; then mkdir downloads fi convert -limit memory 0 -strip +profile "*" -quality 80 $string -append -density 300 -units PixelsPerInch downloads/full.jpg string=*.jpg rm $string下载(fzp.sh)
代码测试此图运行无问题
如果不会使用,我也没办法~自行解决基础问题
下载文件在downloads目录下
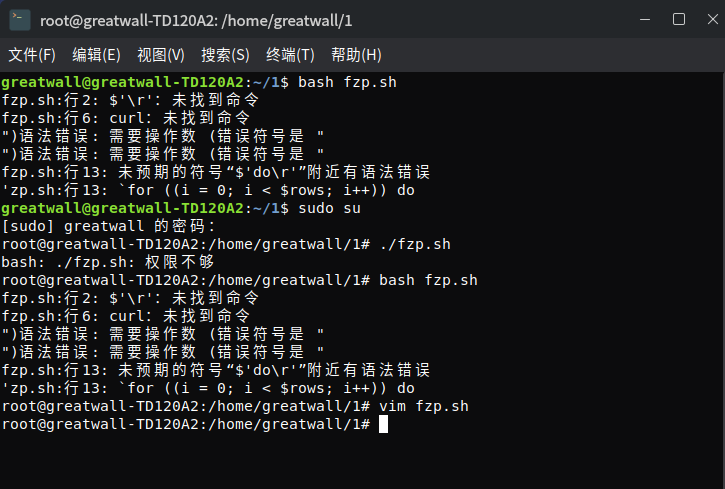
tigershuai游客未曾先生,在Linux上运行fzp.sh时出现以下问题

感觉是代码有语法错误,不知是怎么回事,还望先生能继续解惑。
未曾管理员@tigershuai #46124
可能是编码的问题(我在Windows下保存的这个脚本),你安装一下dos2unix
然后 dos2unix fzp.sh后再执行~
【建议】或者通过vim粘贴代码进去创建文件
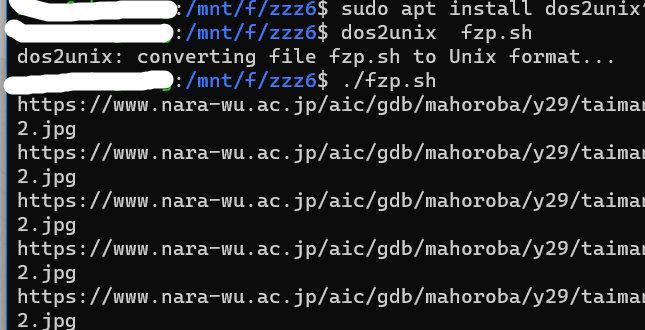
上面的fzp.sh文件我已经重新做了一遍dos2unix。可以重新下载试试
tigershuai游客@未曾 #46125
运行后仍然显示错误
未曾管理员@tigershuai #46140
那你还是下成品图吧,😅
tigershuai游客经过几天都努力,终于解决了运行错误的问题。下面还有一个问题,就是一下子下载几千张小图块,很难保证不出错误图,网络稍微不稳定,就有可能下载到坏图,不知先生是怎么解决这个问题的,还忘赐教。
未曾管理员@tigershuai #46283
我的网络还没遇到这个问题。
如果网络确实有问题,可以调整wget的参数
-T, --timeout=SECONDS 将所有超时设为 SECONDS 秒。 --dns-timeout=SECS 设置 DNS 查寻超时为 SECS 秒。 --connect-timeout=SECS 设置连接超时为 SECS 秒。 --read-timeout=SECS 设置读取超时为 SECS 秒。-t, --tries=NUMBER 设置重试次数为 NUMBER (0 代表无限制)。 --retry-connrefused 即使拒绝连接也是重试。-w, --wait=SECONDS 等待间隔为 SECONDS 秒。 --waitretry=SECONDS 在获取文件的重试期间等待 1..SECONDS 秒。 --random-wait 获取多个文件时,每次随机等待间隔 0.5*WAIT...1.5*WAIT 秒。
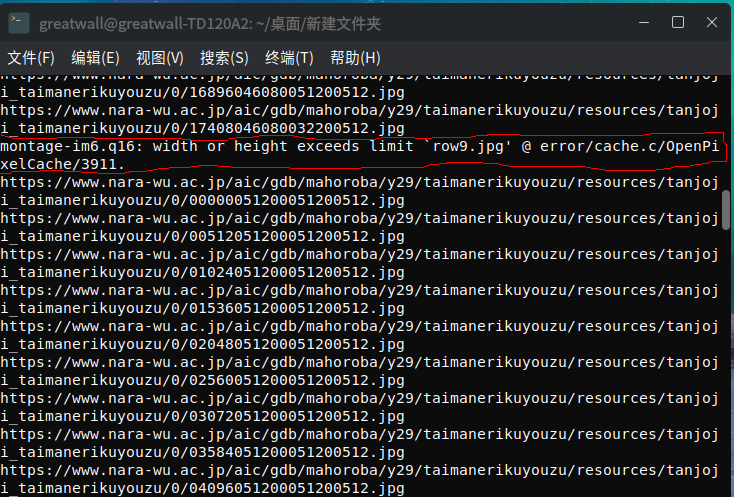
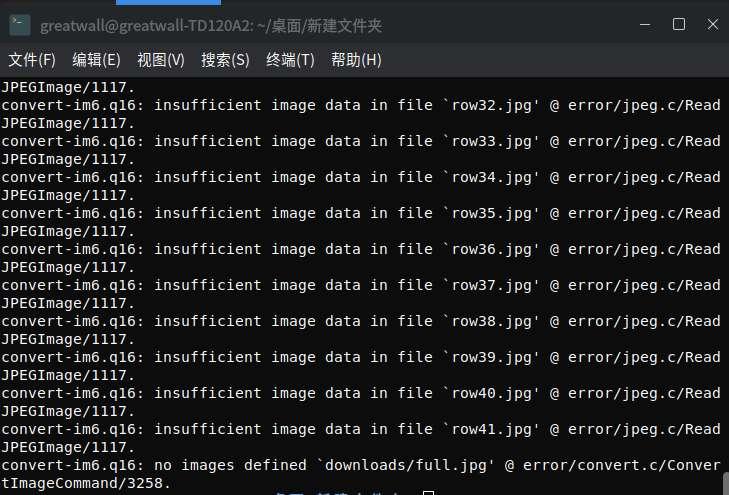
tigershuai游客在运行中出行以下错误(第一张图),最后拼图不成功(第二张图),请问先生是什么原因呢?另外,小图块下载完成后就自动删除了,能不能设置成不自动删除,而由人工手动删除呢。
未曾管理员@tigershuai #46331
提示宽度或高度超出了限制
可能要修改policy.xml文件参数
legacy.imagemagick.org/disco...hp?t=34044不删除碎片的话
#!/bin/bash # Script to download tiles # Last update: 20220520 dzi="https://www.nara-wu.ac.jp/aic/gdb/mahoroba/y29/taimanerikuyouzu/resources/tanjoji_taimanerikuyouzu/root.xml" xml=
curl -s ''$dzi''wi=(echo $xml | sed 's/.*width=\"\([0-9]*\).*//g') hi=(echo $xml | sed 's/.*height=\"\([0-9]*\).*//g') tsize=(echo $xml | sed 's/.*tilewidth=\"\([0-9]*\).*//g') url=echo ${dzi/root.xml/}"0/" cols=$((wi/tsize+1)) rows=$((hi/tsize+1)) for ((i = 0; i < $rows; i++)) do string='' for ((j = 0; j < $cols; j++)) do if [ $i -lt $((rows-1)) ] ; then nh=$tsize else nh=$((hi%tsize)) fi if [ $j -lt $((cols-1)) ] ; then nw=$tsize else nw=$((wi%tsize)) fi num1=echo $((j*tsize))|awk '{printf("%05d\n",$0)}'num2=echo $((i*tsize))|awk '{printf("%05d\n",$0)}'num3=echo $nw |awk '{printf("%05d\n",$0)}'num4=echo $nh |awk '{printf("%05d\n",$0)}'image=$num1$num2$num3$num4'.jpg' img=$j'_'$i'.jpg' file=$url$image echo $file string=$string' '$img wget --no-check-certificate --user-agent="Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.204 Safari/534.16" -c -t 40 -O $img $file -q done montage $string -tile $cols''x1 -mode concatenate row$i.jpg done string='' for ((i = 0; i<$rows; i++)) do string=$string' 'row$i.jpg done if [ ! -d "downloads" ]; then mkdir downloads fi convert -limit memory 0 -strip +profile "*" -quality 80 $string -append -density 300 -units PixelsPerInch downloads/full.jpg string=row*.jpg rm $string
tigershuai游客@未曾 #46339
我运行的就是您上面提供的fzp.sh那个文件,没做修改。我怀疑是不是imagemagick安装有问题?
未曾管理员@tigershuai #46357
前面已经说了,应该是系统分配给imagemagick 的资源不够处理大的图片。建议修改policy.xml文件参数
policy.xml一般位于/etc/ImageMagick-*/目录下
修改(参考值或根据自己电脑调整)如下
…… <policy domain="resource" name="memory" value="16GiB"/> <policy domain="resource" name="map" value="16GiB"/> <policy domain="resource" name="width" value="128MP"/> <policy domain="resource" name="height" value="128MP"/> <!-- <policy domain="resource" name="list-length" value="128"/> --> <policy domain="resource" name="area" value="16GiB"/> <policy domain="resource" name="disk" value="30GiB"/> ……
张飞白游客感谢@未曾先生分享经验
我有一个想法:
它的左上角(第一张)的碎图链接为:
htt ps://www.nara-wu.ac.jp/aic/gdb/mahoroba/y29/taimanerikuyouzu/resources/tanjoji_taimanerikuyouzu/0/00000000000051200512.jpg
右下角(最末一张)的碎图链接为:
htt ps://www.nara-wu.ac.jp/aic/gdb/mahoroba/y29/taimanerikuyouzu/resources/tanjoji_taimanerikuyouzu/0/17408209920032200243.jpg
可以看出.jpg前面的那串数字是递加的,在找不出规律的情况下,可以用穷举法进行下载(至少通用图片下载器可以这样,对于中间不存在、错误的链接,则下载不成功,下载完毕后即是全部碎图),待下载完后,再用本地拼接工具进行拼图。
只是如把数字整体当变量,这个变量也太过巨大。请问先生它的碎图的数字变化规律是什么??相邻碎图的数字差值是多少?(如差值比较大,则生成的碎图链接数量会控制在较小的范围)
还望先生解答,谢谢。
未曾管理员@张飞白 #54013
你看脚本应该能发现
就是碎片位置数*碎片大小(然后不足五位前面填充)XY两个参数,组合碎片大小宽高两个参数。共四个参数组合而成
num1=echo $((j*tsize))|awk '{printf("%05d\n",$0)}' num2=echo $((i*tsize))|awk '{printf("%05d\n",$0)}' num3=echo $nw |awk '{printf("%05d\n",$0)}' num4=echo $nh |awk '{printf("%05d\n",$0)}' image=$num1$num2$num3$num4'.jpg'
墨雲游客@张飞白 #54013
htt ps://www.nara-wu.ac.jp/aic/gdb/mahoroba/y29/taimanerikuyouzu/resources/tanjoji_taimanerikuyouzu/0/00000000000051200512 第一张图的后面的两个512,代表碎片图的长宽,大部分图长宽都是512,除了最后那一行的图长宽不是标准的512 但可以根据上面的格式可以知道最后一行的图长宽为322和243
htt ps://www.nara-wu.ac.jp/aic/gdb/mahoroba/y29/taimanerikuyouzu/resources/tanjoji_taimanerikuyouzu/0/17408209920032200243.jpg
然后上面最后那幅图322两个0前则为长宽的叠加,各占5位数,先长后宽
可惜现在取消了文字颜色没法很好标注
对了能再分享一下你那个分析香港中文大学jp2链接的小程序吗
墨雲游客
未曾管理员
空层游客
未曾管理员@空层 #54031
程序不是会自动拼接好到downloads目录下吗?
空层游客@未曾 #54034
不知道是网速的原因,还是环境没有搭建好,下载的好慢。向您请教的时候是600多个碎片,我以为下载完了但是没有合成整图,可是问完之后发现又多了一些碎片,实在抱歉。现在过去2个多小时了还没下载完。顺便问下是等碎片全部下载完后在下载碎片的文件夹里生成一个downloads文件吗?
未曾管理员@空层 #54040
程序是这样的设定,最终会拼成一个大图到downloads文件夹
张飞白游客感谢指导。
我根据碎图链接规律也制作了一个下载器,有兴趣的朋友可以试一下。
--来自百度网盘超级会员V5的分享
hi,这是我用百度网盘分享的内容~复制这段内容打开「百度网盘」APP即可获取
链接:pan.baidu.com/s/152...TFE6L3tw2A
提取码:f19d第一次尝试了直接解析、拼接在线图片,而不是下载到本地后再拼接,以及进度条的实现。算是技术上新的突破。
未曾管理员@张飞白 #54097
感谢分享
远方游客@未曾 #54098
末曾老师您好,张飞白老师分享的这个碎图下载器你有收藏吗?因为想下载横滨市立大学的一个资料搜贴看到这个链接,但是张老师的分享已经失效了。如果老师您有麻烦再分享一下。谢谢
张飞白游客【超级会员V6】通过百度网盘分享的文件:奈良国立博物馆图…
链接:pan.baidu.com/s/1vs...A?pwd=1x43
提取码:1x43
复制这段内容打开「百度网盘APP 即可获取」
远方游客@张飞白 #93058
谢谢张老师。
余温游客@张飞白 #93058
正好需要此工具,但链接过期了,能重新发一下吗,多谢!
张飞白游客【超级会员V6】通过百度网盘分享的文件:奈良国立博物馆图…
链接:pan.baidu.com/s/1z2...Q?pwd=5816
提取码:5816
复制这段内容打开「百度网盘APP 即可获取」
芝清游客@张飞白 #99745
先生是否可以再发一遍,全部失效
architc游客@未曾 #45951
版主,“当麻练供养图.17730x21235像素.诞生寺所藏”这张图链接失效,不知可否拨冗恢复一下?谢谢了。
- 作者帖子