- 作者帖子

老杨游客复制黏贴一上午,手指头废了,写了个特简单的批处理,跑起来轻松许多
发布在github上,已经开源,大家可以自己下载使用,上面有使用说明
多年书格老用户,之前一直是浏览,这是第一次发言,感谢未曾先生创建书格,开放共享是推动文化进步的力量
未曾管理员@老杨 #45210
感谢分享,0 level 不一定是最大哦,有时是最小的(例如Google art的网址)。
建议使用 dezoomify-rs -l
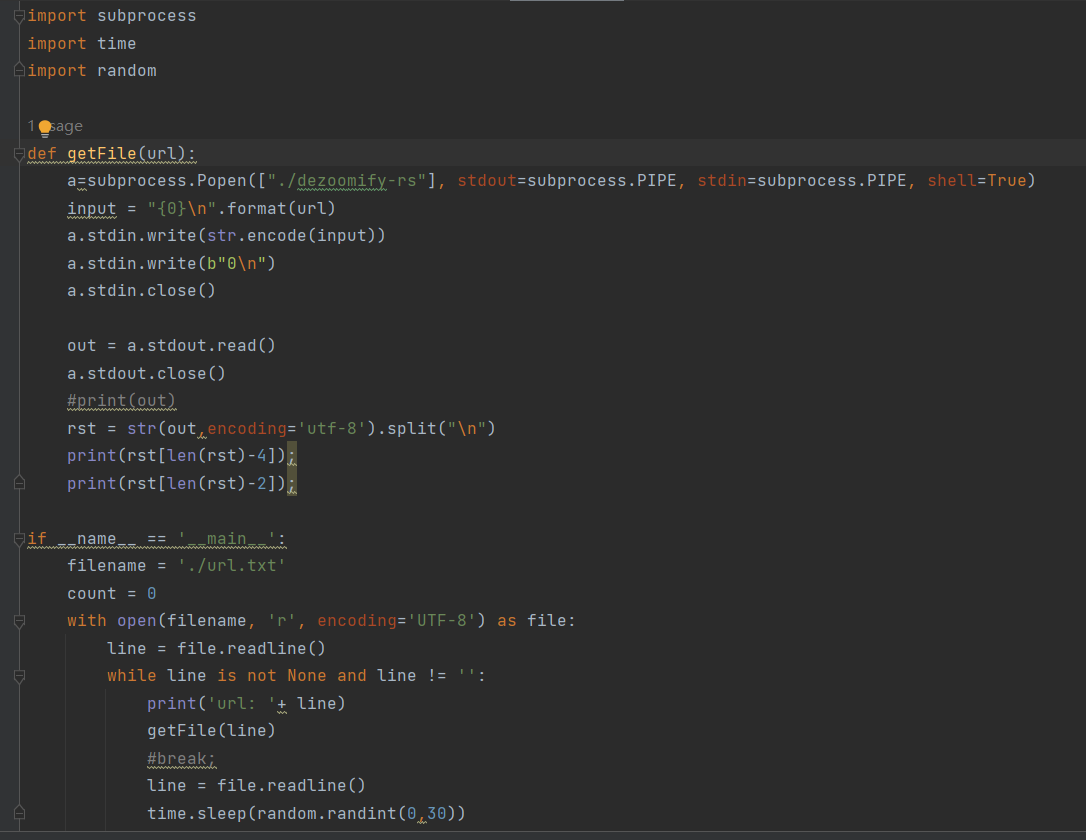
未曾管理员而且这个还要套python啊,我感觉没必要。我大致写了一个bat脚本,仅供参考
@echo off setlocal enabledelayedexpansion set /a a=1 set downdir="download" if not exist %downdir% md %downdir% for /f "delims=" %%i in (urls.txt) do ( dezoomify-rs -l --accept-invalid-certs -H "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36" %%i %downdir%/!a!.jpg set /a a+=1 ) pause
老杨游客@未曾 #45213
头一回用,不知道其他规则是什么样的:)就按测试那个地址写的
@未曾 #45217
这下全了,哪个平台都能用:)
未曾管理员
张飞白游客感谢分享。
个人有两个建议:一是把这个源码打包成工具,大家就能直接用了,第二建议可以增加多线程,下载更快。
我个人也有类似的工具,后面考虑放出来。
tigershuai游客@张飞白 #45277
感謝,書閣里的活雷鋒越來越多了,書友之幸事啊。
老杨游客@张飞白 #45277
我个人提个建议啊,所有的网站可能都不希望有大批量下载,这几乎可以等同于网络攻击,尤其是我看不少朋友希望能下载飞快,所以提个建议,不光给飞白同学,也是给喜爱古籍的大家。
网站一般带宽都比较有限,就好比长安街有5条车道,但二环路只有三条,每个网站的带宽就像车道一样,如果我们开满下载,就相当于我们在车道线上开车,占了两条车道,就会影像其他车辆通行。当咱们下载时候也是这样,如果非常频繁的占用带宽,势必影响其他人正常浏览,大部分网站都会有对访问行为的监控,建议大家使用批量下载最好设置时间间隔,这样即保证了下载,也不会影像其他人浏览,更不会影像网站的正常运行,这才更利于有更多的人看到我们的文明。
未曾管理员@老杨 #45422
赞~
xgdd2018游客@未曾
请问这个批量下载脚本也能套用到mac上吗?
Ajx_@游客
张飞白游客
@Ajx_@ #92568
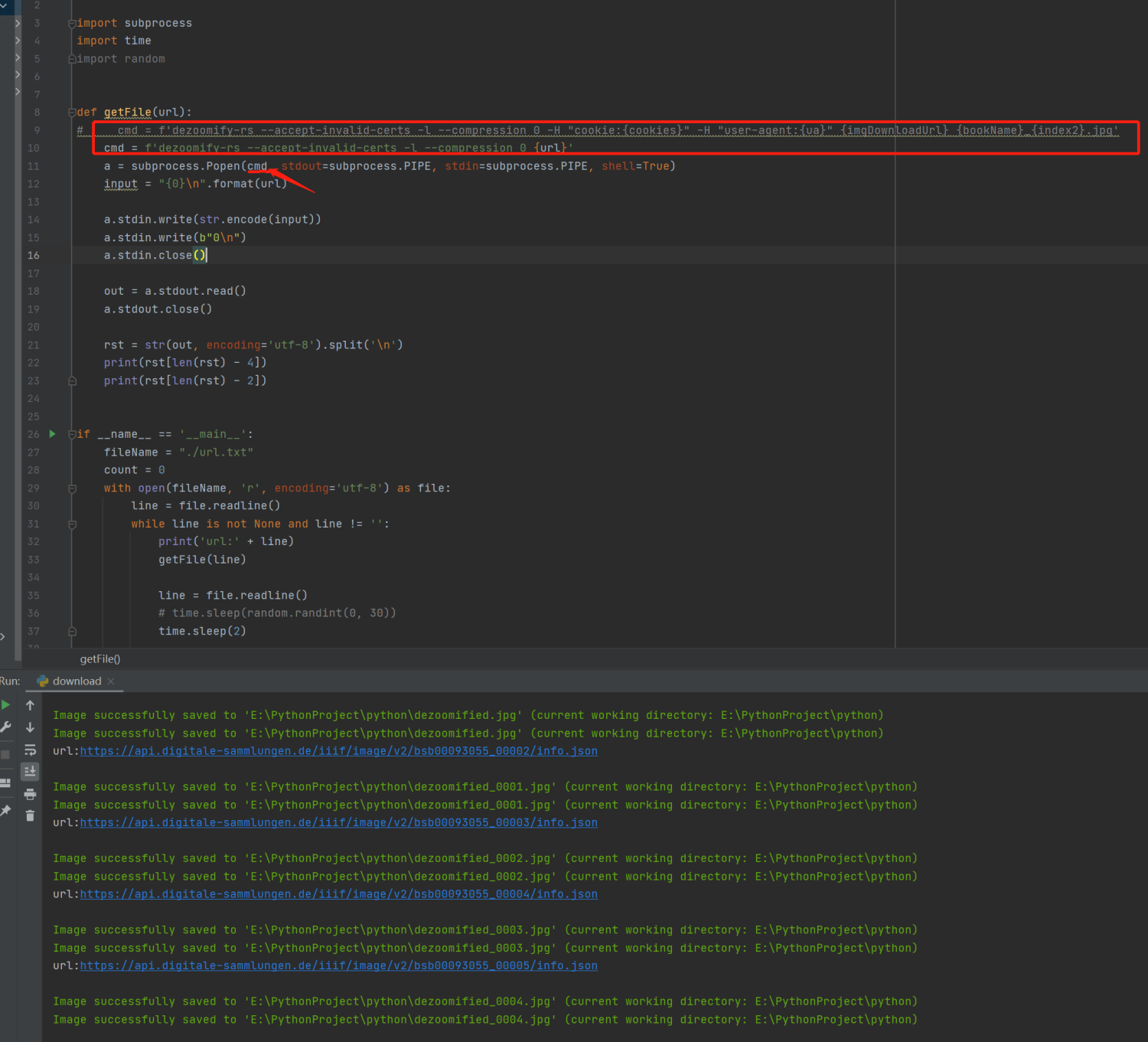
按照您的代码运行一下,确实发现问题,因为您把关键部分搞错了。(就是上头cmd部分)
cmd = f'dezoomify-rs --accept-invalid-certs -l --compression 0 {url}'
其实万变不离其宗,最核心的就是这句,您之前只写了一个“dezoomify-rs”,没有把它相关的命令行写全,显然是不能实现效果的。
但上面这句还是太少了些东西,建议可以增加一些参数,写成这样:
cmd = f'dezoomify-rs --accept-invalid-certs -l --compression 0 -H "cookie:{cookies}" -H "user-agent:{ua}" {url} {bookName}_{index2}.jpg'
增加cookie、ua、referer及保存名称等信息,以适用更多的下载情况。(有些下载没有这些会不成功的)
张飞白游客@Ajx_@ #92568
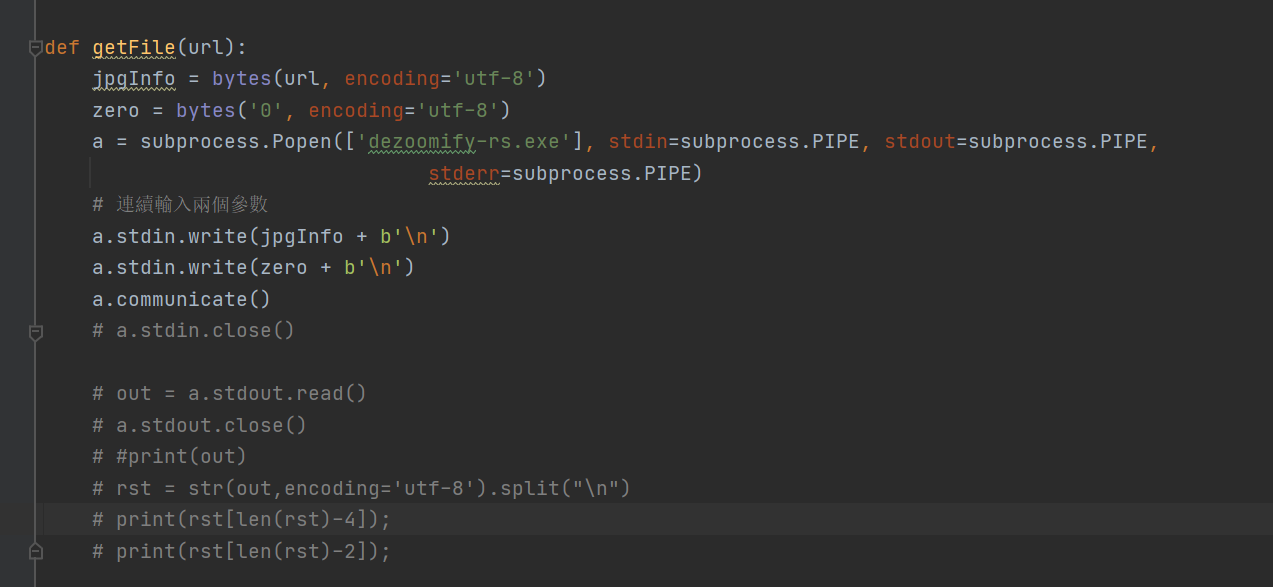
我又仔细看了一下代码,原来是一楼@老杨 #45210写的源码,不知道他当初是否能成功,我测试他的源码确实不成功,不知道哪里出问题了。我观察他的思路,是模拟使用dezoomify-rs工具下载的步骤,共有两步,第一步填入url,第二步填入0(一般是最大);其实此前我也有过类似的想法,按照我之前的代码,把getFile函数里的内容改成下图所示,就能成功了。其实out以下部分是输出提示功能,直接注释掉也可以,就不报错了。
但这种连续输入两个参数的思路也有不完善的地方,其一是如二楼@未曾 #45213说,第二步输入0有时候并不是最大;其二是这样的二步有局限,没有我上一楼说的那样,可以设置多种参数后形成命令行一次性传入,以增加下载的成功性。
最后,最后一行代码,等待时间不需要这么久,等得我好心焦。可以设置数秒即可了。
镜像之美游客请问大侠,这个能否下载[中国]台北古籍与特藏文集?
龙啸游客@未曾 #45423
可以说下故宫数字文物库下载办法吗
xiaopengyou游客
龙啸游客@xiaopengyou #92660
已经失效了
未曾管理员@龙啸 #92661
方法见
www.shuge.org/meet/...post-16727
数字文物库的同样适用
需要到具体的藏品放大的页面执行,如
https://digicol.dpm.org.cn/cultural/details?id=182800测试正常
- 作者帖子
正在查看 19 个帖子:1-19 (共 19 个帖子)

正在查看 19 个帖子:1-19 (共 19 个帖子)
正在查看 19 个帖子:1-19 (共 19 个帖子)
