正在查看 14 个帖子:1-14 (共 14 个帖子)
- 作者帖子

云山游客老师好http://mylib.nlc.cn/web/guest/search/shanbenjiaojuan/medaDataDisplay?metaData.id=6993507&metaData.lId=4225308&IdLib=402834c3409540be0141aa7d72035310这部书有没有获取分页的工具
未曾管理员国图的资源需要带cookies抓取,所以相对麻烦些。而且频繁抓取容易封IP。我抓取了一份此书的分页url列表、
你可以批量下载,单页格式为PDF格式
分页网址txt文件: files.shuge.org/wl/?i...E58sILPRBm
云山游客非常感谢,已经下载,老师能否简要介绍一下 cookies 抓取的方法
未曾管理员大致说一下原理
首先需要找到每册的libId。可以通过正则{libId:\"([0-9a-zA-Z+]+)提取到每册的libId
然后带入cookies获取每个libId页得到totalPageNum(总页码)和medaDataBatch(分册的URLid)两个参数
最后循环批量生成分页url
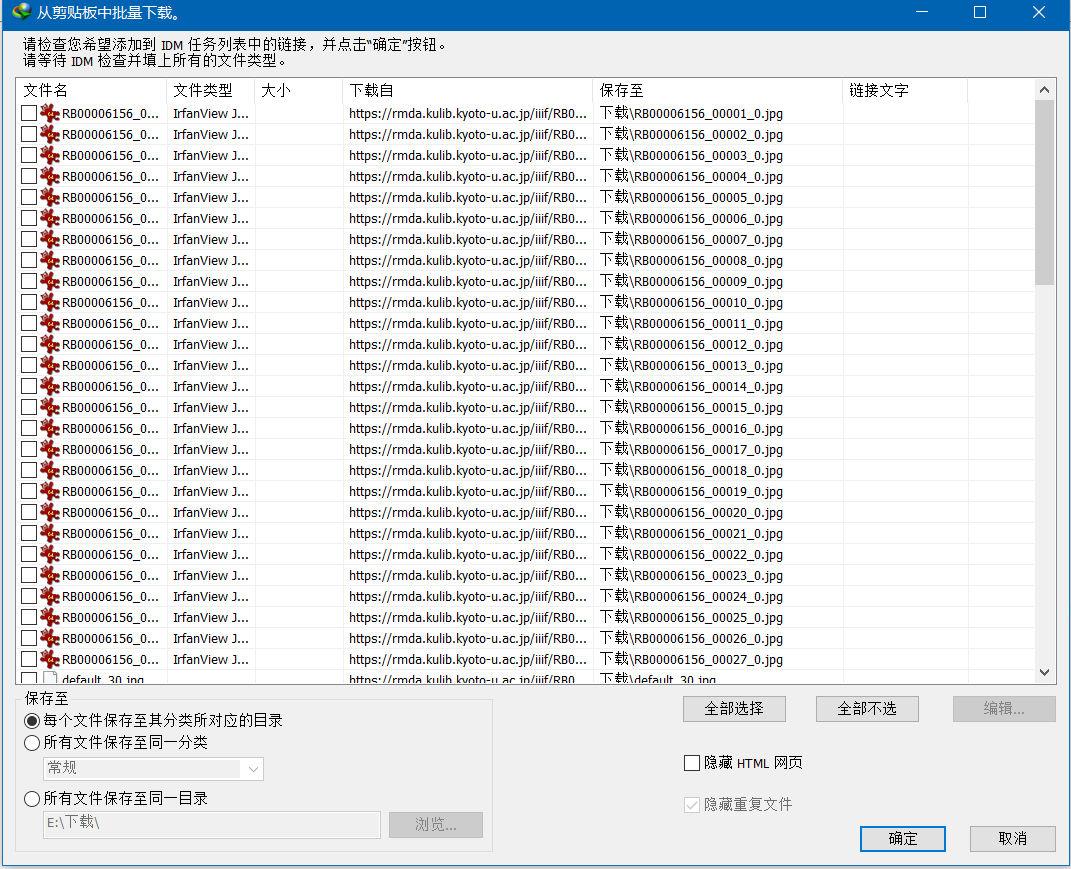
云山游客老师好,京都大学网站好像早晨重新维护了,老师的工具获取的链接,复制进迅雷,连接不到服务器,下载不了。
未曾管理员我测试是正常的,获取的网址可以正常打开。
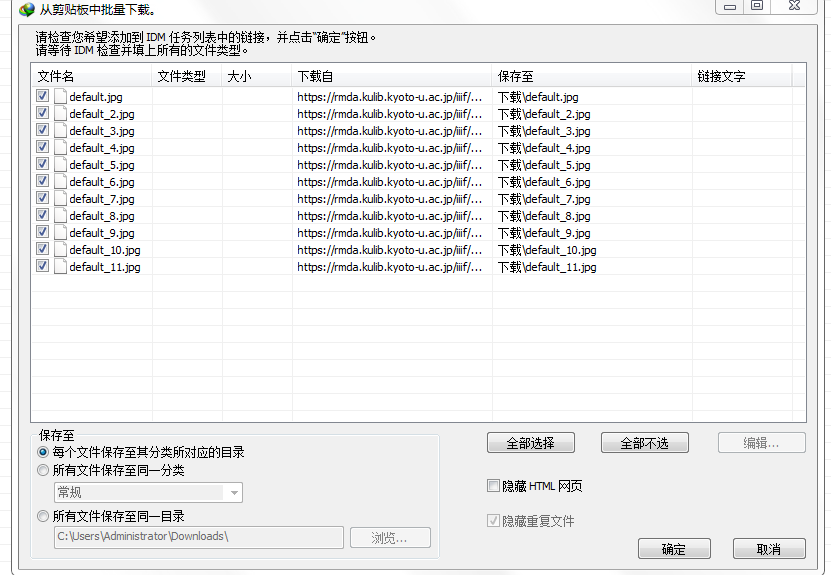
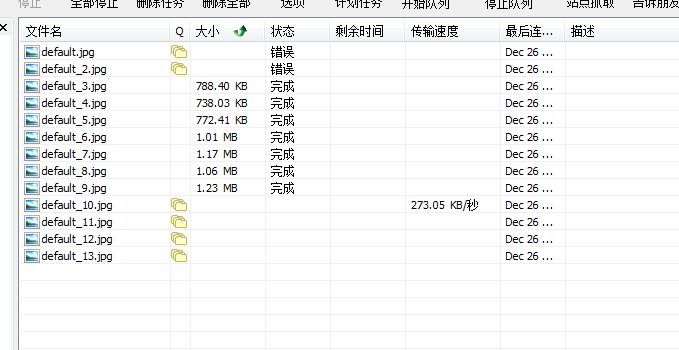
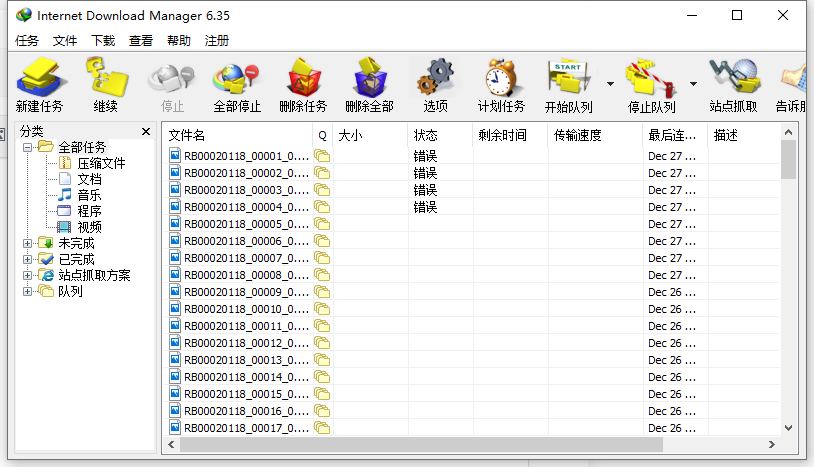
云山游客我这边获取的网址也能正常打开,只是把这些链接复制到迅雷,就连接不到服务器,idm也是一样。
未曾管理员我的测试是正常的

云山游客我这边到这步好像也正常
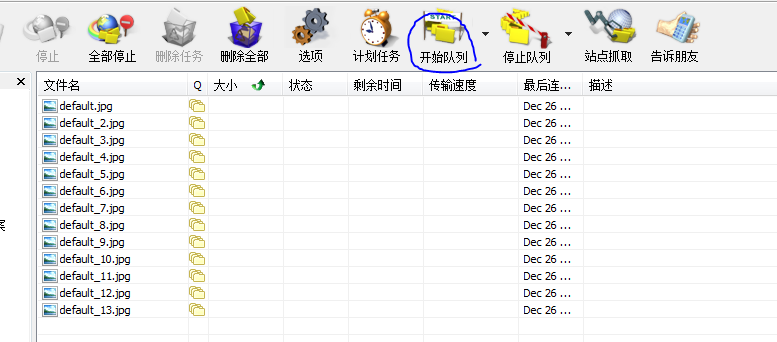
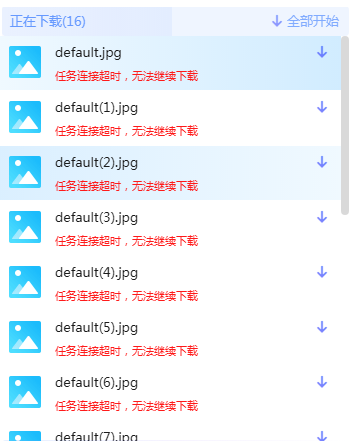
云山游客就是出现在最后执行队列的时候,不开始下载
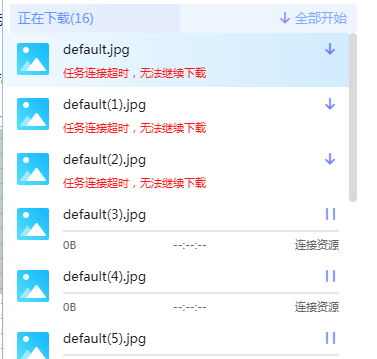
云山游客迅雷的反应是这样
云山游客
云山游客不过这会idm开始下载了,谢谢老师
燃犀小医童游客额,我的为何不行。。。
- 作者帖子
正在查看 14 个帖子:1-14 (共 14 个帖子)
正在查看 14 个帖子:1-14 (共 14 个帖子)
