- 作者帖子

陈经游客未曾先生,您好
按照您的方法: ok.daoing.com/mggh/index.php
下载美国国会图书馆的数字古籍,
由于该套书(https://www.loc.gov/item/00510373/)有一百多册,所有页面下载在同一个文件夹,页码一片混乱。
请问有什么好办法各册下载后被分开在不同文件夹吗?谢谢
未曾管理员@陈经 #10053
这个没有太好的办法,我自己使用的是linux命令行逐行下载后按行号命名
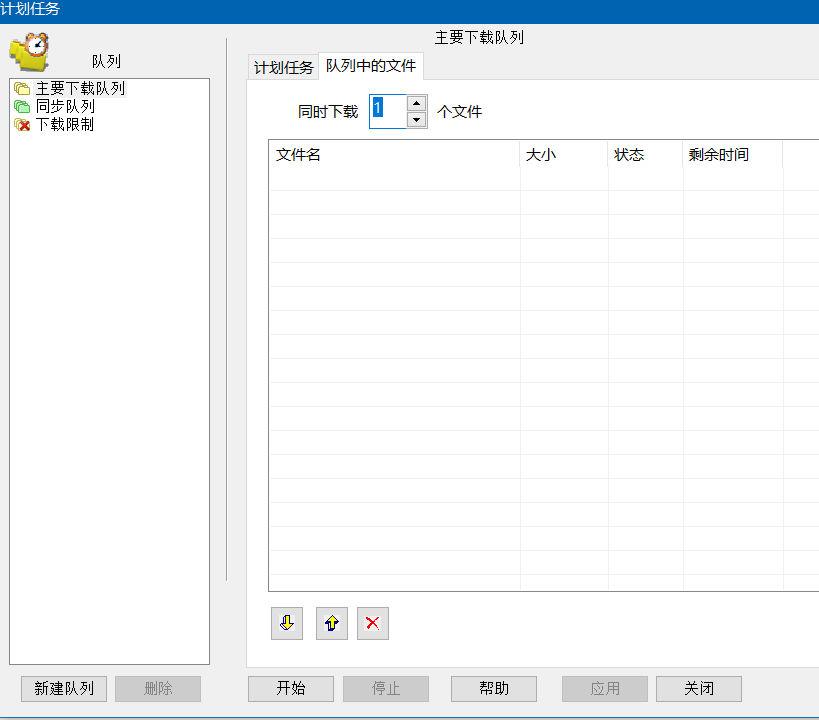
如果使用下载软件的话,我以前提过,使用单次一个下载任务(可以多线程),IDM大概如图

最后按照文件生成时间重命名。
陈经游客谢谢您的非常快速的回复,感恩!
为了提供下载速度,我给迅雷充值了一年的白金会员。使用的是迅雷批量下载。速度倒是不错。
可惜就后期整理、分册太耗时间了。郁闷~
使用IDM,却下载不了,说已存在的链接被远方主机强行关闭!
未曾管理员
未曾管理员其实美国国会图书馆的书,很多自己拍摄的图片顺序本身就有错乱(部分书籍)
洞庭君游客分组下载,批量编号,重新组合,转成PDF,费点时间,好书来之不易。
问书游客美国国会图书馆的书很多本身就次序混乱,但一般都是下一册的首页跑到上一册去了。估计是整理的人不懂中文造成的。我一般是手动调整,比较费时。
下载的时候,可以用wsl写个脚本,下载时自动根据链接次序加上编号,这样就次序不乱了。请参考:
#!/bin/bash name=1 while read line do wget -O $(printf "%06d" $name)_${line##*/} -nc -w 8 --random-wait -T 15 $line let name+=1 done < url.txturl.txt是保存的链接文件。
另外,有些书卷数比较多,页面链接经常生成不完整,比如9000多页的资治通鉴,不能获取完整的页面链接。未曾先生可否解决这个问题呢?
未曾管理员@问书 #11245
9690页应该是完整的页数吧。有时连续读取的页面太多,可能有网络问题,多试几次就好了
如果你说的是这个:資治通鑑 : 二百九十四卷, 附釋文辯誤十二卷
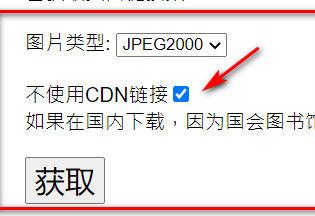
www.loc.gov/item/2014514219/一直无法获取的话。可以下载我获取的JP2URL.TXT
shuge.cowtransfer.com/s/e266ef588e8d40如果需要tif,替换JP2URL.TXT中链接的.jp2为.tif
问书游客多谢,现在能获取完整了!
- 作者帖子
正在查看 9 个帖子:1-9 (共 9 个帖子)
正在查看 9 个帖子:1-9 (共 9 个帖子)
正在查看 9 个帖子:1-9 (共 9 个帖子)
